Long time ago I had written a C++ library to parse ARFF files for one of my Machine-Learning projects. Today, I'm making the code open-source! Here's the link to the code hosted on github: https://github.com/teju85/ARFF. This also comes with doxygen documentation for the API exposed by this library and also has unit-tests (written using google-test) for CYA.
Showing posts with label programming. Show all posts
Showing posts with label programming. Show all posts
Monday, September 5, 2011
Sunday, August 28, 2011
Iterator for templated STL containers in C++
I realized this today! The following code almost always will give compilation error.
std::vector::const_iterator itr;
And the compilation error (with g++ version 3.4.6) will be as vague as:
error: expected `;' before "itr"
The solution is to just do the following:
typename std::vector::const_iterator itr;
Thursday, July 28, 2011
How to request 'super user' permission from your app?
NOTE: This blog assumes that you have installed Superuser application installed on your device! Also, I'm not responsible for any bricked devices!
Process p;
try {
p = Runtime.getRuntime().exec("su");
}
catch(IOException e) {
e.printStackTrace();
}
This will pop up a window from 'Superuser' application which will ask user to whether allow your app to be given 'su' permissions or not. Users can either 'Allow' or 'Deny' and also set 'Remember this option' on this window.
Hope this helps!
Hope this helps!
Tuesday, June 21, 2011
Java API for Bitly webservice
I wrote a Java API for Bitly webservice (details about this webservice can be found here). It provides a easy interface to the output of the webservice, by parsing the JSON format and storing the values in the corresponding variables inside an appropriate 'BitlyResponse' object. This could be a very useful API for accessing url-shortening services from inside java apps (could be for android as well!). You can find the jar file and the relevant code at the following github repo: git@github.com:teju85/BitlyAPI.git
PS: There's no restriction on the using this library, provided you acknowledge the use of this API in your application. :)
PS: There's no restriction on the using this library, provided you acknowledge the use of this API in your application. :)
Friday, June 17, 2011
CorrDim: a fast correlation dimension evaluator
After going through this blog written by Bill Maier, I thought why not I give a shot in writing a C++ program to find the correlation dimension and figure out its performance. 'CorrDim' is the result of this. This has some of the most common maps already available within the project folder viz: Logistic map, Tent map and Henon map. Also, adding a map of your choice is a piece of cake, thanks to virtual inheritance. Go through the 'README' file available in the source code to know more on how build and extend this to include more maps. This program supports 2 modes of correlation dimension evaluation:
- Fast but huge memory: In this mode, the distance matrix will be evaluated apriori so that the subsequent lookups are faster. However, this requires huge memory, especially if the number of elements considered is huge.
- 'Relatively' fast but consumes little memory: In this mode, the distance matrix will be evaluated on-the-fly, during the evaluation of the correlation dimension, thus requiring very little memory.
The choice of the mode depends on: If you absolutely cannot sacrifice even a little performance, then you should use the normal version. But for all practical purposes, it is recommended that you use the low-memory version.
Profiling:
Here are the results from profiling this program [Results are on a Dell-Latitude E6400, with Ubuntu 10.10 installed and on LogisticMap.]...
Memory Profiling:
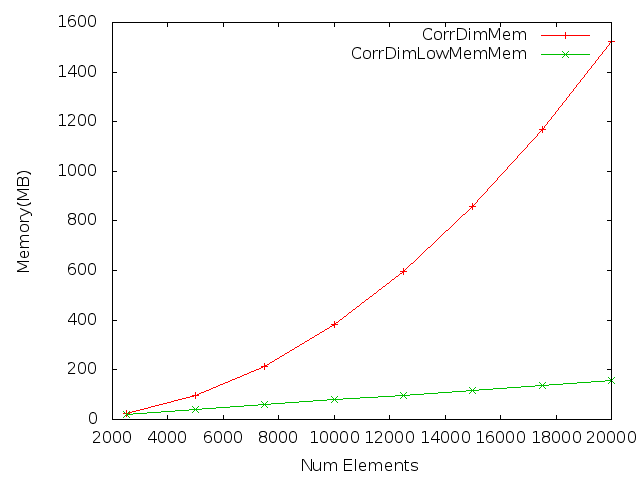
Run-time profiling:

As you can see, the LowMemory version of this program gives a significant reduction in memory footprint compared to its counterpart. At the same time, the performance loss is also not that noticeable.
I have hosted this project (open-source'd with GPL) on github at: git@github.com:teju85/CorrDim.git.
Wednesday, June 8, 2011
Replacing tabs with spaces in eclipse
Tabs are evil! They are interpreted differently by different editors. So, it is always better to setup your editor to replace tabs with a constant number of spaces. IMO, 4 spaces will be visually appealing. While working with eclipse, here's how to set this property: (assuming eclipse version "Helios Service Release 2")
Window -> Preferences -> Java -> Code Style -> Formatter -> New
Give your profile a name, something like 'Eclipse [only-spaces]' and inherit all the basic settings from the 'Eclipse [built-in]' profile. (You can choose to inherit from whichever other profile of your interest or you can directly edit one of your favorite profiles. For me, the built-in profile was sufficient). Also make sure that 'Open the edit dialog now' is checked in and then press 'Ok'.
In the dialog box which opens, select Indentation -> Tab policy -> Spaces only.
Set the 'Indentation size' and 'Tab size' to 4. (meaning 4 spaces, as I mentioned in the beginning).
Press Apply to save all your settings and from here onwards, eclipse will put spaces instead of tabs for the indentation!
The reason I created a new profile is because one can keep re-using this in all your future projects and also has the ability to export your profiles when you want to use this profile on some other machine!
Monday, May 9, 2011
Sudoku checker
Time for another home assignment! :P
Given a solved sudoku board, the aim is to check whether it is a valid solution or not. The program pasted below will do the same. In fact, it prints out ALL the offending rows, columns and blocks (if the solution is not valid). The idea is simple, if a row/column/block has all its elements to be unique, then the sum of all it's elements will be (N*(N+1))/2, where NxN is the size of the sudoku board.
#include <stdio.h>
void isCorrect(int** grid, int N, int sqrootN) {
int sum = (N * (N + 1)) >> 1;
// all rows
for(int i=0;i<N;i++) {
int actual = 0;
for(int j=0;j<N;j++) {
actual += grid[i][j];
}
if(actual != sum) {
printf("Row '%d' is incorrect!\n", i+1);
}
}
// all columns
for(int i=0;i<N;i++) {
int actual = 0;
for(int j=0;j<N;j++) {
actual += grid[j][i];
}
if(actual != sum) {
printf("Column '%d' is incorrect!\n", i+1);
}
}
// all blocks
for(int i=0;i<N;i+=sqrootN) {
for(int j=0;j<N;j+=sqrootN) {
int actual = 0;
for(int a=0;a<sqrootN;a++) {
for(int b=0;b<sqrootN;b++) {
actual += grid[i+a][j+b];
}
}
if(actual != sum) {
printf("Block starting at '%d,%d' is incorrect!\n", i+1,j+1);
}
}
}
}
int main(int argc, char** argv) {
if(argc == 2) {
FILE* fp = fopen(argv[1], "r");
if(fp == NULL) {
fprintf(stderr, "Failed to open '%s' for reading!\n", argv[1]);
return 1;
}
int N, sqrootN;
int** grid;
fscanf(fp, "%d", &N);
fscanf(fp, "%d", &sqrootN);
grid = new int* [N];
for(int i=0;i<N;i++) {
grid[i] = new int [N];
for(int j=0;j<N;j++) {
fscanf(fp, "%d", &(grid[i][j]));
}
}
isCorrect(grid, N, sqrootN);
for(int i=0;i<N;i++) {
delete grid[i];
}
delete grid;
fclose(fp);
}
else {
fprintf(stderr, "USAGE: %s <file>\n", argv[0]);
return 1;
}
return 0;
}
How to compile?
(Assuming the above program is saved in the file sudokuChecker.cpp)
g++ -o checker sudokuChecker.cpp
How to run?
./checker <file>
<file> = the file containing the sudoku board
Saturday, May 7, 2011
Finding (and printing) cycles in a directed graph
I know... this seems some kind of under-grad assignments. But I was feeling boring last night and hence decided to write this code to kill time. I spent about 20-30 minutes in coming up with this program. The program is available at git://github.com/teju85/Cycles.git. This code takes a file as input (containing the adjacency matrix for the graph of interest) and prints all the elementary cycles in the directed graph.
PS: However, I haven't tested this code rigorously, yet! So, if you find any issues with this code, just drop in a comment here and I'll take a look into it.
PS: However, I haven't tested this code rigorously, yet! So, if you find any issues with this code, just drop in a comment here and I'll take a look into it.
Friday, April 29, 2011
How to find the size of a file in C++?
We need to use the combination of fseek and ftell functions. Here's one such implementation. This implementation will return a '-1' in case it'll not be able to open the file, else returns the size of the file (in B).
#include <stdio.h>
/**
* @brief Finds the size of the file (in B)
* @param file name of the file
* @return if file-open fails, returns a value of -1; else size of the file.
*/
int sizeOfFile(const char *file) {
FILE* fp = fopen(file, "rb");
if(fp == NULL) { return -1; }
fseek(fp, 0, SEEK_END);
int i = ftell(fp);
fclose(fp);
return i;
}
I tried to verify the performance of the above function, using the piece of code below:
int main(int argc, char** argv) {
if(argc != 2) {
fprintf(stderr, "USAGE: %s <fileToBeRead>\n", argv[0]);
return 1;
}
for(int i=0;i<10000;i++) {
sizeOfFile(argv[1]);
}
return 0;
}
I copied above 2 pieces of code into a file named 'test_perf.cpp'. Then, I compiled using the command: 'g++ -o perf test_perf.cpp' in cygwin version 1.7. Here's my result: [System: Dell Latitude E6400, Win7, 32b]
$ time ./perf.exe perf.exe real 0m2.677s user 0m0.342s sys 0m1.887s $ stat perf.exe File: `perf.exe' Size: 19596 Blocks: 20 IO Block: 65536 regular file .... some more outputs hidden for privacy reasons ....
Monday, April 18, 2011
cutop: GPU version of 'top'
Here's a tool I wrote today for for mimicking the functionality of the famous unix tool 'top'. The idea is to give the user the capability to monitor how the resource usage is going on in the GPU's. Currently, this tool does not do much, but only monitors the memory usage of the GPU's. In the future releases of this tool, I'm planning to add more functionalities. Ofcourse, assuming that I get hold of the NVML API as soon as possible! (fingers crossed).
But till then, I've hosted the project over github and you can access the source code from here: (read-only) 'git://github.com/teju85/cutop.git'.
Wednesday, April 6, 2011
Minimum resolution of the C 'clock' function
Here is the C program to find out the minimum resolution of the 'clock' function on your system.
#include <time.h>
#include <stdio.h>
int main(int argc, char** argv) {
clock_t a, b;
a = b = clock();
while(a == b) {
b = clock();
}
printf("Minimum resolution by 'clock()' = %lf s\n",
((double) (b - a))/CLOCKS_PER_SEC);
return 0;
}How to compile? (assuming that you have stored this program in a file named 'minRes.c')
gcc -o minRes minRes.c
How to run?
minRes
On my system (Dell Latitude E6400, running Win7), I got this to be about 15ms, on an average.
What about you?
Sunday, January 2, 2011
Kaprekar-Numbers
Kaprekar-numbers are interesting. For eg.: 703 is a kaprekar-number. Reason: 7032 = 494209 and 494 + 209 = 703. It's also been proven that one can get all the Kaprekar-numbers by prime factorization of 10n-1. However, I wanted to list all the Kaprekar-numbers by solving it in its pure form! A number 'k' (in base 10) is called as Kaprekar-number if it can be expressed in the form:
k = q + r and k2 = q * 10n + r
Where, q >= 1, 0 < r < 10n
I've hosted this program on github at the following location (read-only): git://github.com/teju85/Kaprekar-Numbers.git. If you are interested in this, please download the program and follow the instructions inside the 'README'.
I profiled this program and here are the results:
$ make profile printCpuInfo.sh Processor Information: processor : 0 vendor_id : GenuineIntel model name : Intel(R) Xeon(R) CPU X5355 @ 2.66GHz kaprekarnumber -nooutput -profile -limit 10000 Found 17 kaprekar-numbers among first '10000' integers. Took 0.001309 seconds to search for self-numbers among these integers. kaprekarnumber -nooutput -profile -limit 100000 Found 24 kaprekar-numbers among first '100000' integers. Took 0.014230 seconds to search for self-numbers among these integers. kaprekarnumber -nooutput -profile -limit 1000000 Found 54 kaprekar-numbers among first '1000000' integers. Took 0.188414 seconds to search for self-numbers among these integers. kaprekarnumber -nooutput -profile -limit 10000000 Found 62 kaprekar-numbers among first '10000000' integers. Took 1.616492 seconds to search for self-numbers among these integers.
Not sure whether the timings are 'optimal' or not. Still looking for possible optimizations...
Tuesday, December 21, 2010
Self-numbers
For any given base, a number is called as Self-number, if it cannot be represented as a sum of another integer and the sum of this integer's digits. Hmm... seems like a pretty simple coding-task. Indeed it is! Sat for about half-an-hour and here (released under GNU-GPL) is the program which can generate first 'n' self-numbers for base 10. I profiled this code and given below are the results:
$ make profile printCpuInfo.sh Processor Information: processor : 0 vendor_id : GenuineIntel model name : Intel(R) Xeon(R) CPU E5450 @ 3.00GHz selfnumber -nooutput -profile -limit 1000001 Found 0 self-numbers among first '1000000' integers. Took 0.004973 seconds to search for self-numbers among these integers. selfnumber -nooutput -profile -limit 10000001 Found 0 self-numbers among first '10000000' integers. Took 0.060016 seconds to search for self-numbers among these integers. selfnumber -nooutput -profile -limit 100000001 Found 0 self-numbers among first '100000000' integers. Took 0.597042 seconds to search for self-numbers among these integers. selfnumber -nooutput -profile -limit 1000000001 Found 0 self-numbers among first '1000000000' integers. Took 5.440813 seconds to search for self-numbers among these integers.
~5ms for 1 million numbers seems like pretty fast. Isn't it?
UPDATE1:
I moved this program to github. Read-only access for this is at git://github.com/teju85/Self-Numbers.git. I also optimized the inner loop to perform modulus operations only for one in 100 numbers. This way, I was able to reduce the run-time to 2ms for 1 million numbers!
UPDATE1:
I moved this program to github. Read-only access for this is at git://github.com/teju85/Self-Numbers.git. I also optimized the inner loop to perform modulus operations only for one in 100 numbers. This way, I was able to reduce the run-time to 2ms for 1 million numbers!
$ make profile printCpuInfo.sh Processor Information: processor : 0 vendor_id : GenuineIntel model name : Intel(R) Xeon(R) CPU X5355 @ 2.66GHz selfnumber -nooutput -profile -limit 1000001 Found 97786 self-numbers among first '1000000' integers. Took 0.002037 seconds to search for self-numbers among these integers. selfnumber -nooutput -profile -limit 10000001 Found 977787 self-numbers among first '10000000' integers. Took 0.018121 seconds to search for self-numbers among these integers. selfnumber -nooutput -profile -limit 100000001 Found 9777788 self-numbers among first '100000000' integers. Took 0.185008 seconds to search for self-numbers among these integers. selfnumber -nooutput -profile -limit 1000000001 Found 97777789 self-numbers among first '1000000000' integers. Took 1.789393 seconds to search for self-numbers among these integers.
Subscribe to:
Comments (Atom)